What is Fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It is hosted by the Cloud Native Computing Foundation (CNCF) as a sandbox project. Fluid is can convert distributed caching systems (such as Alluxio and JuiceFS) into observable caching services with self-management, elastic scaling, and self-healing capabilities, and it does so by supporting dataset operations. At the same time, through the data caching location information, Fluid can provide data-affinity scheduling for applications using datasets.
Target Scenario and Values
In the treand of computation and stroage separation, the goal of Fluid is to enable AI/Big Data Applications to use data from any storage more efficiently with a high-level abstraction manner and without changes to the applications themselves.
Unlike traditional PVC-based storage abstraction, Fluid takes an Application-oriented perspective to abstract the “process of using data on Kubernetes”. It introduces the concept of elastic Dataset and implements it as a first-class citizen in Kubernetes to enable Dataset CRUD operation, permission control, and access acceleration.
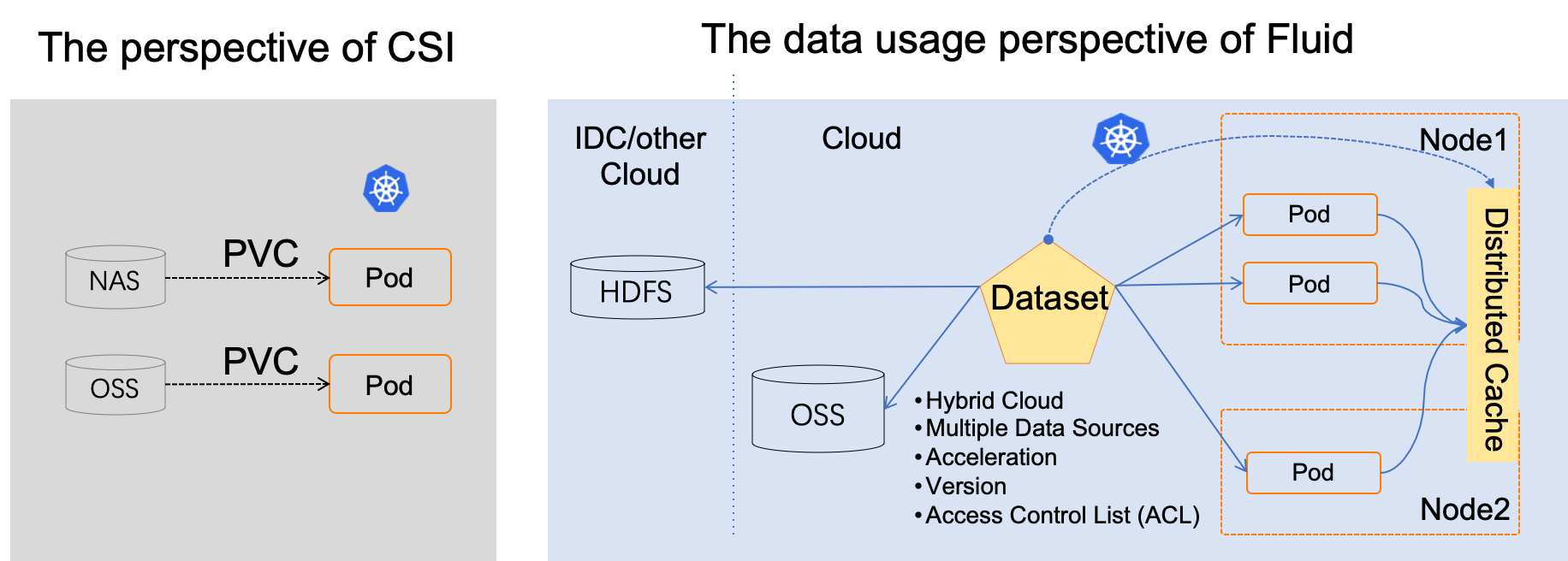
Through the data abstraction layer powered by Fluid on Kubernetes, the data will just be like the fluid, waving across the storage sources (such as HDFS, OSS, Ceph) and the cloud native applications on Kubernetes. It can be moved, copied, evicted, transformed and managed flexibly. Besides, All the data operations are transparent to users. Users do not need to worry about the efficiency of remote data access nor the convenience of data source management. User only need to access the data abstracted from the Kubernetes native data volume, and all the left tasks and details are handled by Fluid.
Fluid aims to turn different distributed cache systems (Alluxio, JuiceFS, Vineyard, CubeFS and so on) into self-managing, self-scaling, self-healing and observable cache services inside of Kubernetes by providing the common framework of Fluid.
Fluid enables Kubernetes schedulers to make intelligent, topology-aware scheduling plans regarding where the distributed data cache system is located. It focuses on the dataset orchestration and application orchestration scenarios. The dataset orchestration can arrange the cached dataset to the specific Kubernetes node, while the application orchestration can arrange the the applications to nodes with the pre-loaded datasets. These two can work together to form the co-orchestration scenario, which take both the dataset specifications and application characteristics into consideration during resouce scheduling.
Fluid presents its value in the following two aspects:
- Use the power of Kubernetes platform to deliver its services via a Kubernetes Operator for each distributed cache provider, and automate the tasks of the administrator: deployment, bootstrapping, configuration, provisioning, scaling, upgrading, monitoring, data prefetch, data migration and resource management.
- Help the users make the most of distributed caching by combining third-party caching systems with Kubernetes scheduling and elasticity, also aligning them with specific application data usage scenarios and methods.
Why Fluid
-
Running AI, big data and other tasks on the cloud through a cloud-native architecture can take advantage of the elasticity of computing resources, but at the same time, it also faces data access latency and large bandwidth overhead due to the separated computing and storage architecture. Especially deep learning training with GPUs, iterative remote access to large amounts of training data will significantly slow down the computing efficiency.
-
Kubernetes provides heterogeneous storage service access and management standard interface (CSI, Container Storage Interface), but it does not define how the application uses and manages data. When running machine learning tasks, data scientists need to be able to define file features of the dataset, manage versions of the dataset, control access permissions, pre-process the dataset, accelerate heterogeneous data reading, etc. However, there is no such standard scheme in Kubernetes, which is one of the important missing capabilities of Kubernetes.
-
Kubernetes supports a variety of forms, such as native Kubernetes, edge Kubernetes and Serverless Kubernetes. However, for different forms of Kubernetes, the support for CSI plug-ins is also different, for example, many Serverless Kubernetes do not support the deployment of third-party CSI plug-ins.
In summary, to resolve the issue that Kubernetes lacks the awareness and optimization for application data, Fluid put forward a series of innovative methods such as co-orchestration, intelligent awareness, joint-optimization, to form an efficient supporting platform for data-intensive applications in cloud native environment.
System Characteristics
-
Application-oriented DataSet Unified Abstraction:DataSet not only consolidates data from multiple storage sources, but also describes the data's portablity and features, also providing observability, such as total data volume of the DataSet, current cache space size, and cache hit rate. Users can evaluate whether a cache system needs to be scaled up or down according to this information.
-
Lightweight but highly extensible Runtime Plugins:Dataset is an abstract concept, and the data operation needs to be implemented by the Runtime. According to the different storages, there will be different Runtime interfaces. Fluid's Runtime is divided into two categories: CacheRuntime to accelerate data access, such as AlluxioRuntime for S3, HDFS and JuiceFSRuntime for JuiceFS; the other category is ThinRuntime, which provides a unified access interface to facilitate the access to third-party storage.
-
Automated data operation:Providing data prefetch, migration, backup and other operations via CRDs, and supporting various trigger modes such as one-time, scheduled, and event-driven, to facilitate users to integrate them into the automated operation and maintenance system.
-
Data elasticity and scheduling:By combining distributed data caching technology with autoscaling, portability, observability, and affinity scheduling capabilities, data access performance can be improved through the provision of observable, elastic scaling cache capabilities and data affinity scheduling capabilities.
-
Runtime platform Agnostic:Support diverse environments such as native, edge, Serverless Kubernetes cluster, Kubernetes multi-cluster, and can run in various environments such as cloud platform, edge, Kubernetes multi-cluster. It can run storage client in different modes by choosing CSI Plugin and sidecar according to the differences in environments.
Publication
For more information of our key ideas, please refer to our papers:
-
Rong Gu, Kai Zhang, Zhihao Xu, et al. Fluid: Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs. IEEE ICDE, pp. 2183-2196, May, 2022. (Conference Version)
-
Rong Gu, Zhihao Xu, Yang Che, et al. High-level Data Abstraction and Elastic Data Caching for Data-intensive AI Applications on Cloud-native Platforms. IEEE TPDS, pp. 2946-2964, Vol 34(11), 2023. (Journal Version)