Metabit Trading's Case Study
This article introduces the support of elastic quantitative investment and research of public cloud based on Fluid + JuiceFSRuntime
By Zhiyi Li and Jianhong Li
The advances in machine learning, cloud computing, cloud-native, and other technologies have injected new impetus into the innovation of the financial industry. A typical example is Metabit Trading, a technology-based quantitative trading company with artificial intelligence as its core. They have created long-term and sustainable returns for investors by deeply integrating and improving machine learning algorithms and applying them to financial data with low signal-to-noise ratios.
Unlike traditional quantitative analysis, machine learning focuses on structured data (such as stock prices, trading volumes, and historical returns) and injects unstructured data from research reports, financial reports, news, and social media to gain insight into security price movements and volatility. However, it is challenging to apply machine learning to quantitative studies because the raw data may contain noises. In addition, they need to deal with many challenges (such as unexpected tasks, high concurrent data access, and computing resource constraints).
Metabit Trading continues to make efforts in R&D investment, innovation support, and basic platform construction to solve these problems. Their research infrastructure team has built an efficient, secure, and scalable R&D process of tool chain, breaking through the limitations of stand-alone R&D by leveraging cloud computing and open-source technology. This article shares the specific practices of the basic platform for quantitative research and introduces the support of elastic quantitative investment and research of public cloud based on Fluid + JuiceFSRuntime.
A Detailed Explanation of Quantitative Research
As an AI-powered hedge fund, strategy research through AI model training is our main research method. First, we need to extract features from the raw data before training the model. The signal-to-noise ratio of financial data is low. If we directly use raw data for training, the resulting model will be noisy. In addition to market data (such as stock price and trading volume that we often see in the market), raw data includes some non-volume and price data (such as research reports, financial reports, news, social media, and other unstructured data). Researchers will extract features through a series of transformations and then train AI models. You can refer to the following simplified diagram of the strategy research pattern that is most closely related to machine learning in our research scenario.
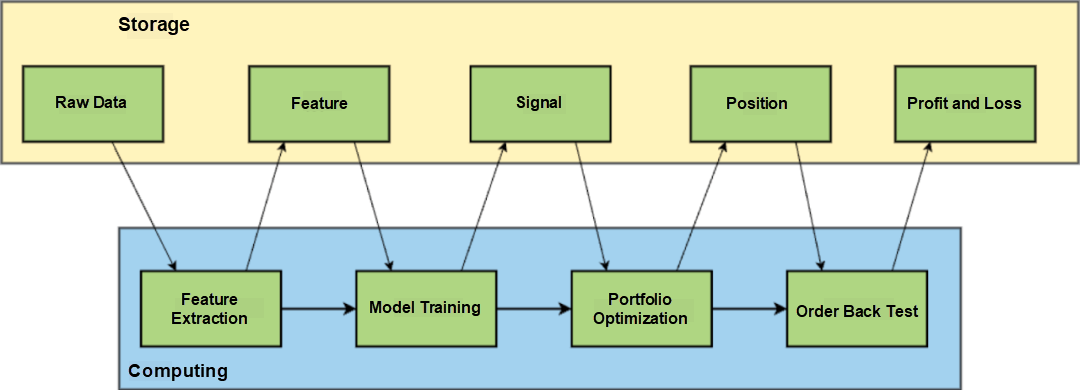
Model training produces models and signals. A signal is a judgment about future price trends, and the strength of the signal means the strength of strategic orientation. The quantitative researcher will use this information to optimize the portfolio to form a real-time position for trade. In this process, the horizontal dimension (stocks) will be considered for risk control. For example, do not excessively hold stocks in a particular industry. When a position strategy is formed, quantitative researchers will place simulated orders and get the profit and loss information corresponding to the real-time position to understand the profit of the strategy. This is a complete process of quantitative research.
Requirements for Quantitative Research Basic Platform
-
There are many unexpected tasks and high elasticity requirements. In the process of strategy research, quantitative researchers will generate strategic ideas and test their ideas through experiments. Therefore, computing platforms will generate a large number of unexpected tasks, so we have high requirements for computing Auto Scaling capability.
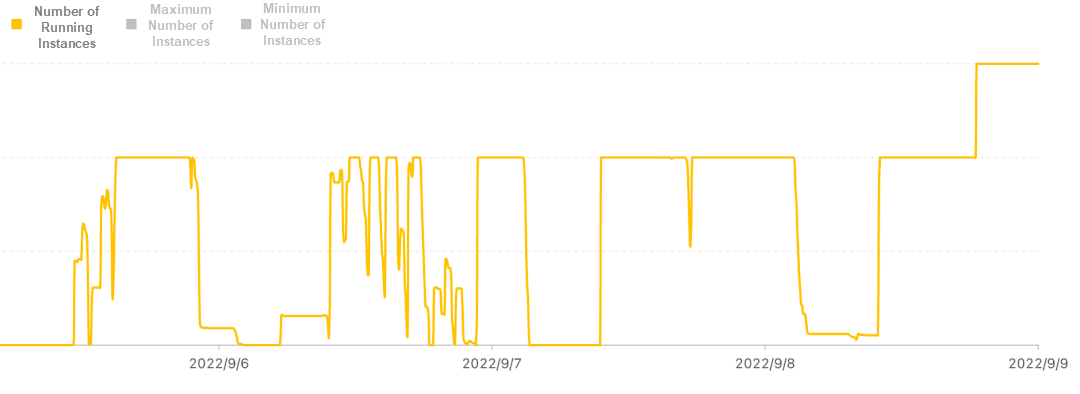
The preceding figure shows the running instance data of a cluster over a period. Take it as an example: the number of instances of the whole cluster can reach thousands at peak hours in multiple time periods, but at the same time, the scale of the computing cluster can be scaled in to zero. There is a strong correlation between the computing tasks of quantitative institutions and the researcher's R&D progress. There are big gaps between peaks and troughs, which is also a feature of offline research tasks.
-
Hot data is accessed in a high-concurrency scenario. In addition to computing, data caching requires elasticity. For hot data (such as market data), there are usually hundreds of tasks accessing data at the same time, and it has very high throughput requirements. At its peak, the aggregate bandwidth of hundreds of Gbps (or even Tbps) is required. However, when there are no nodes in the computing cluster, the throughput requirement is 0. If the throughput is rigid, elastic throughput scaling is required.
-
It is important to perform financial model training to have independent linear extensibility of capacity and throughput. Traditional distributed storage bandwidth and throughput are only proportional to data usage capacity. However, during quantitative research, a large number of containers are created to concurrently access the data of the storage system, which triggers access limiting of the storage system. This leads to the mismatch between the ultrahigh elasticity of computing resources and the limited bandwidth of the storage system. However, the amount of data for quantitative research is not particularly large, and the total amount of volume and price data in many markets will not exceed the TB level. However, the peak throughput required for data access is very high.
-
Data affinity scheduling. The same data source accessing local cache multiple times can be reused. Give full play to the advantages of cache nodes of hot datasets and intelligently schedule tasks to data cache nodes without disturbing users' perceptions. Thus, common model training programs can be faster.
-
IP Protection – Data Sharing and Data Isolation: For IP protection, it is important to isolate in computing tasks and have access control ability for data. At the same time, it is important to support researchers to obtain public data (such as market data) in a convenient way.
-
Cache Intermediate Results: In scenarios where computing tasks are modularized, storage and transmission of intermediate results are also required. For example, a large amount of feature data will be generated during feature computing, and these data will be immediately used on the following large-scale and highly concurrent training nodes. In this scenario, we need a high-throughput and high-stability intermediate cache for data transmission.
-
Support for Multiple File Systems: Different types of computing tasks will correspond to different data types and usage. Therefore, our teams will use different file systems (including OSS, CPFS, NAS, and JuiceFS) to optimize the performance in respective situations. Different runtime of Fluid can flexibly support the combination of file systems and tasks, so task computing can use corresponding resources on Kubernetes in a more efficient and reasonable manner and avoid unnecessary waste.
Fluid + JuiceFSRuntime: Provide Efficient Support for Quantitative Research Basic Platform on the Cloud
Considering POSIX compatibility, cost, and high throughput, we chose the JuiceFS cloud service as the distributed basic storage. After choosing JuiceFS, we found that the existing CSI system of Kubernetes cannot support our requirements for data access performance, elastic throughput, and data sharing and isolation well. Specifically:
-
The traditional Persistent Volume Claim is designed for general storage and lacks good support for the access mode of complex data stored in the same storage. In different application scenarios, applications use different files in the same storage in different ways. For example, most concurrent computing tasks require read-only. However, there are also Pipeline data transfers. After data features are generated, they need to be transferred to model training, which requires reading and writing. This makes it difficult to uniformly set metadata update and cache policy in the same PVC. These policies should depend on the patterns in which the application uses the data.
-
Data Isolation and Sharing: Different data teams need to be isolated and require easy management when accessing different datasets. At the same time, it supports access and sharing of public datasets, especially cache data sharing. Public data (such as market data) will be used repeatedly by different teams of researchers, and they hope to obtain the effect of getting all things done once and forever.
-
Data Cache-Aware Kubernetes Scheduling: Jobs with the same model, the same input, and different super parameters and jobs with fine-tuning models and the same input will repeatedly access the same data, resulting in reusable data caches. However, the native Kubernetes scheduler is not cache-aware, resulting in poor application scheduling, unreusable cache, and no performance improvement.
-
Data access throughput can be flexibly scaled out to hundreds of Gbit/s: For a traditional distributed file storage with high performance, its general storage specification is 200 MB/s/TiB baseline and has a maximum IO bandwidth of 20 Gbit/s, while the peak IO bandwidth of our task requires at least hundreds of Gbit/s. Therefore, the traditional one cannot meet our requirements.
-
Optimal Cost of Data Caching: Public cloud provides extreme elasticity of computing resources, which can create hundreds (or even thousands) of computing instances in a short time. However, when these computing resources access storage at the same time, the throughput needs to be hundreds of Gbit/s or more at peak hours. As such, it is necessary to serve hot data through the cache cluster in computing. However, in many time periods, the computing cluster will be scaled in to 0. At this time, it is not worth maintaining a large cache cluster. We prefer to warm up data before use and perform regular scale-in and scale-out according to the running rules of the business. When no jobs are running in the computing cluster, scale in to the default cache node to achieve dynamic Auto Scaling control of data cache throughput.
To this end, we are eager to find software on Kubernetes that has elastic distributed cache acceleration capability and has good support for JuiceFS storage. We found that Fluid 1 works well with the JuiceFS storage, and the JuiceFS team happens to be the main contributor and maintainer of JuiceFSRuntime in the Fluid project. Therefore, we designed the architecture solution based on Fluid and chose the native JuiceFSRuntime.
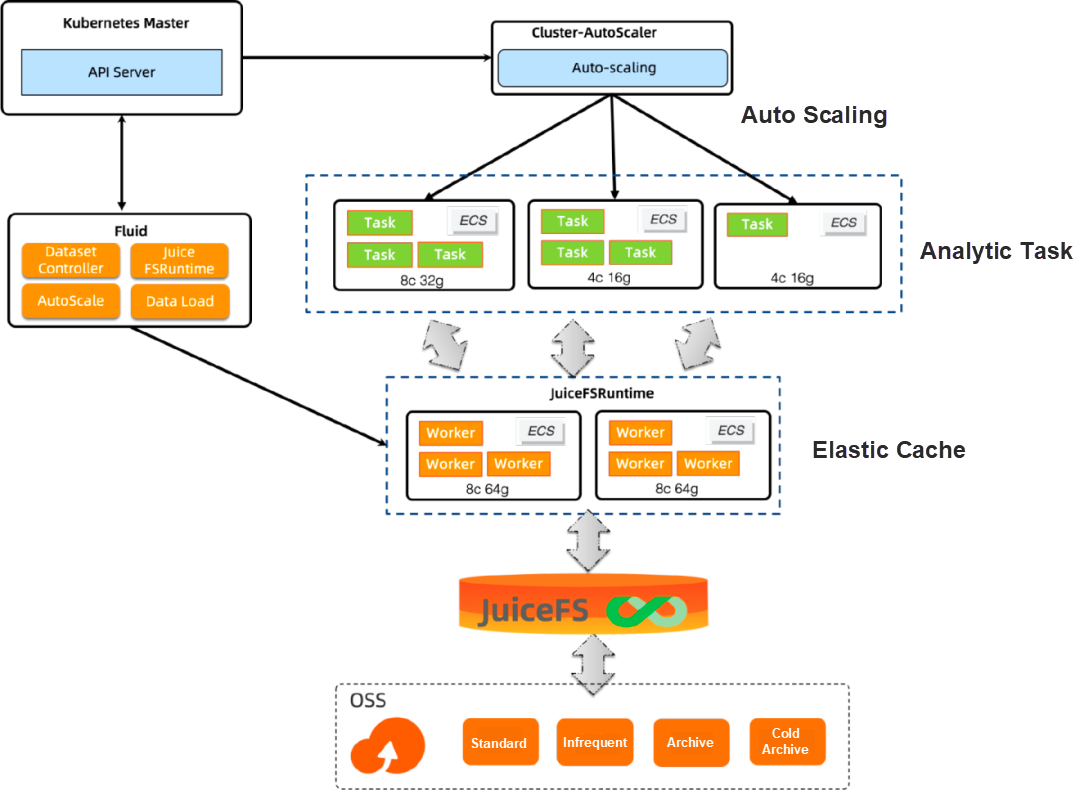
An Introduction to Architecture Components
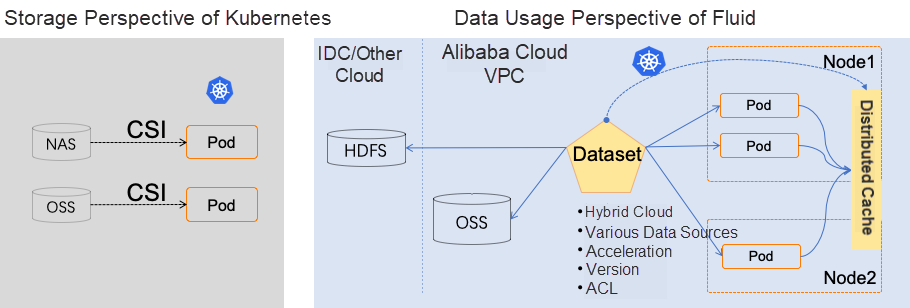
Fluid
Fluid is different from the traditional storage-oriented PVC abstraction. Instead, it abstracts the process of computing the data used by tasks on Kubernetes. It puts forward the concept of an elastic Dataset, which is centered on the application's demand for data access and gives features to the data, such as small files, read-only, and read-write. At the same time, extract data from the storage and give scopes to the data with features (such as the data that users only care about for a few days). Build a scheduling system centered on Dataset, focus on the orchestration of the data itself and the applications that use the data, and emphasize elasticity and lifecycle management.
JuiceFSRuntime
Based on the distributed cache acceleration engine of JuiceFS, JuiceFSRuntime combines the distributed data cache technology with the Auto Scaling, portability, observability, and scheduling capabilities of Fluid to support scenario-based data caching and acceleration. JuiceFSRuntime is easy to use and deploy on Fluid. It is compatible with the native Kubernetes environment and is out-of-the-box. It also integrates the storage features of JuiceFS to optimize data access performance in specific scenarios.
Reasons to Use JuiceFSRuntime-Based Fluid
-
Dataset abstraction meets various requirements (such as performance optimization, isolation, and sharing) in cloud-native machine learning scenarios:
- Scenario-Based Performance Tuning: Dataset allows you to optimize datasets with different access features. For example, model training scenarios are usually read-only, while feature computing requires read-write.
- Data Isolation: Dataset restricts access permissions of different teams to datasets in the cluster through the resource isolation mechanism of Kubernetes namespace. Different datasets correspond to different subdirectories in JuiceFS (JuiceFS Enterprise Edition also supports directory quotas), which can meet the requirements of data isolation.
- Data Cache Sharing: Fluid supports data access across Kubernetes namespaces for some public datasets frequently used by different teams, which can be cached once and shared by multiple teams. This also meets the requirements for data cache sharing.
-
Scenario-Based Optimization of Computing Resource of Runtime: Dataset is a general abstraction of data, and the actual operation of data is implemented by JuiceFSRuntime. Therefore, the resource configuration of Runtime (such as CPU, memory, network, and the number of cache workers) will affect the performance. Therefore, it is necessary to optimize the computing resources of Runtime according to the usage scenario of Dataset.
-
Elastic Distributed Cache: Support a wide range of scale-in and scale-out policies (including manual scaling, auto scaling, and scheduled scaling). You can find the optimal elastic solution as needed.
- Manual Scaling: The observability of Dataset allows you to understand the data amount of dataset and the cache resources required by the cache Runtime. You can set the number of Replicas (the number of cache workers) of Runtime based on the concurrency of application access and scale in during the idle time.
- Auto Scaling: Carry out Auto Scaling based on data metrics. For example, caching Auto Scaling can be carried out according to metrics (such as data cache volume and throughput). Automatic scale-out can be carried out when the cache percentage exceeds 80% or when the number of clients exceeds a certain threshold.
- Scheduled Scaling: You can set scheduled scaling based on the business features to implement unattended data elastic scaling.
-
Automatic Data Preheating: It can avoid data access competition caused by concurrently pulling data at the training time and cooperate with Auto Scaling to avoid premature creation of cache resources.
-
Data-Aware Scheduling Capability: When an application is scheduled, Fluid provides the data cache location as scheduling information to the Kubernetes scheduler through JuiceFSRuntime to help the application schedule to cache nodes or nodes closer to the cache. The entire process is transparent to users, maximizing the benefits of data access performance.
Implementation Practice
According to practice, we have summarized the following experience for your reference.
Select ECS with Large Memory and IO with High Network as Cache Nodes in JuiceFSRuntime of Fluid
With the continuous improvement of ECS network capability, the capability of the current network bandwidth has far exceeded the IO capability of SSD. Take ECS of the ecs.g7.8xlarge specification on Alibaba Cloud as an example: its peak bandwidth is 25 Gbit/s, and its memory is 128 GiB. In theory, it only takes 13s to read 40 GB of data. Our data is stored in JuiceFS. Therefore, to realize large-scale data reading, we need to load the data to the computing nodes in the VPC network where the computing happens. Here is a specific example that we used. In order to speed up data reading, we configure the cache node to choose memory for data caching. Note:
- Worker is mainly responsible for distributed data caching. We can configure a model with relatively high memory performance for Worker to speed up data reading. The scheduling policy of Worker is configured in Dataset. Therefore, you need to configure an affinity policy for Worker in Dataset.
- In order to ensure that AutoScaler of Cluster scale out successfully, it is recommended to select multiple instance types in configuring affinity to ensure successful scale-out and task execution when a task has no specific model requirements.
- Replicas is the initial number of cache workers, which can achieve scale-in and scale-out later through manual triggering or auto scaling.
- After you specify tieredstore, it is unnecessary to set the memory of the request in the Pod of Kubernetes. Fluid can handle it automatically.
- For example, the JuiceFS mount on the cache node has different configurations (such as the cache size and mount path), which can be overwritten by options in worker.
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:
name: metabit-juice-research
spec:
mounts:
- name: metabit-juice-research
mountPoint: juicefs:///
options:
metacache: ""
cache-group: "research-groups"
encryptOptions:
- name: token
valueFrom:
secretKeyRef:
name: juicefs-secret
key: token
- name: access-key
valueFrom:
secretKeyRef:
name: juicefs-secret
key: access-key
- name: secret-key
valueFrom:
secretKeyRef:
name: juicefs-secret
key: secret-key
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values:
- ecs.g7.8xlarge
- ecs.g7.16xlarge
tolerations:
-key: jfs_transmittion
operator: Exists
effect: NoSchedule
---
apiVersion: data.fluid.io/v1alpha1
kind: JuiceFSRuntime
metadata:
name: metabit-juice-research
spec:
replicas: 5
tieredstore:
levels:
- mediumtype: MEM
path: /dev/shm
quota: 40960
low: "0.1"
worker:
nodeSelector:
nodeType: cacheNode
options:
cache-size: 409600
free-space-ratio: "0.15“
Configuring Auto Scaling Policies
Due to the business type, Metabit has higher usage requirements in a fixed period. Therefore, an Auto Scaling policy that configures scheduled cache nodes can achieve good benefits (such as cost control and performance improvement).
apiVersion: autoscaling.alibabacloud.com/v1beta1
kind: CronHorizontalPodAutoscaler
metadata:
name: research-weekly
namespace: default
spec:
scaleTargetRef:
apiVersion: data.fluid.io/v1alpha1
kind: JuiceFSRuntime
name: metabit-juice-research
jobs:
- name: "scale-down"
schedule: "0 0 7 ? * 1"
targetSize: 10
- name: "scale-up"
schedule: "0 0 18 ? * 5-6"
targetSize: 20
Furthermore, if specific metrics in the business (such as cache ratio threshold and IO throughput) trigger Auto Scaling policies with complex custom rules, a more flexible scaling configuration of cache nodes can be achieved, thus achieving higher and more stable performance. Specifically, there are some advantages in terms of flexibility and performance:
- It is unnecessary to accurately detect the bottom data or have fixed scaling rules. You can adaptively configure the upper and lower limits of cache replicas based on the cluster status.
- Stepwise scale-out avoids creating too many ECS instances at the beginning to avoid waste in spending.
- Avoid bandwidth preemption caused by explosive ECS accessing to JuiceFS data.
Trigger Data Preheating
Increase the cache ratio through data preheating and then trigger auto scaling. At the same time, monitor the cache ratio. When the cache ratio reaches a certain threshold, it starts to trigger task delivery to avoid the IO latency caused by the premature delivery of highly concurrent tasks.
Image Embedding
Due to the large scale of computing and data elasticity used by Metabit Trading, a large number of Pods pop up in an instant, resulting in image download throttling. Network bandwidth resources are scarce during pod pull-up. In order to avoid various problems caused by the latency in pulling up container images during pod creation, we recommend that ECS images be customized, and the required systematic images be buried to reduce the time cost of pod pull-up. Please refer to the base image of ACK for specific examples.
Performance and Cost Benefits from Increased Elastic Throughput
In the actual deployment evaluation, we use 20 ECS instances of ecs.g7.8xlarge specifications as worker nodes to build a JuiceFSRuntime cluster. The maximum bandwidth of a single ECS node is 25 Gbit/s. We use memory to cache data and speed up data reading.
For comparison, we counted the access time data and compared it with the access time by using Fluid. The data is shown in the following figure:

When the number of Pods that are started simultaneously is small, Fluid has no significant advantage over distributed storage. However, when more Pods are started at the same time, Fluid has a greater acceleration advantage. When the concurrency is expanded to 100 Pods at the same time, Fluid can reduce the average time consumption by more than 40% compared with traditional distributed storage. On the one hand, it improves task speed. On the other hand, it saves the cost of ECS due to IO latency.
More importantly, the data read bandwidth of the entire Fluid system is positively correlated with the size of the JuiceFSRuntime cluster. If we need to scale more Pods out at the same time, we can modify the Replicas of JuiceFSRuntime to increase the data bandwidth. This dynamic scaling capability is unavailable for distributed storage.
Outlook
Metabit has taken a solid first step in the practice of Fluid. We are also thinking about how to use this continuously innovating and outputting technology framework to exert its complete functions in more suitable scenarios. This is a summary of some of our small observations. It serves as a catalyst for further discussion.
-
Serverless can provide better elasticity: Currently, we use custom images to improve the elasticity efficiency of application containers and Fluid components. We also find that using Fluid on ECI can provide more efficient and simple application extension elasticity while reducing O&M complexity. This is a direction worth exploring in practice.
-
Collaboration between Task Elasticity and Data Cache Elasticity: The business system understands the number of concurrent tasks that use the same dataset over a period and performs data preheating and elastic scaling during task queuing. Correspondingly, when the data cache or data access throughput meets certain conditions, the queued tasks are triggered from waiting to being available.
Summary and Acknowledgements
Metabit Trading has been using Fluid in the production environment for nearly a year and a half, including JindoRuntime and JuiceFSRuntime. Currently, it realizes efficient large-scale quantitative research through JuiceFSRuntime. Fluid delivers the benefits of simplicity, stability, reliability, multiple runtimes, easy maintenance, and transparency to quantitative researchers.
The large-scale practice of Metabit Trading has helped our team build a good understanding of using public clouds. In scenarios of machine learning and big data, elasticity is necessary for computing resources and its corresponding data access throughput. It is difficult for traditional storage-side caches to meet the needs of current scenarios due to the differences in cost, flexibility, and on-demand elasticity, while the concept and implementation of computing-side elastic data caching of Fluid are more suitable in current scenarios.
Special thanks to Weiwei Zhu (of JuiceData) and Yang Che, Zhihao Xu, and Rong Gu (of Fluid Community) for their continuous support. Thanks to their maintenance, there is active discussion and quick response in the community, which plays a key role in our smooth adoption.
About the Author
Zhiyi Li (Metabit Trading - AI Platform Engineer) is a builder, cloud-native technology learner, and former Senior Engineer of Citadel.
Jianhong Li (Metabit Trading - Engineering Manager of AI Platform) focuses on building machine learning platforms and high-performance computing platforms in the quantitative research field. He was a Senior Engineer at Facebook.