Weibo's Case Study
This article introduces a new architecture solution based on Fluid (containing JindoRuntime) designed and implemented by Weibo's technical teams.
By Wu Tong and Hao Li, Engineers of Weibo Deep Learning Platform
The deep learning platform plays an important role in Weibo's social business. Under the architecture where computing and storage are separated, there is a problem of low performance in data access and scheduling in Weibo's deep learning platform. This article introduces a new architecture solution based on Fluid (containing JindoRuntime) designed and implemented by Weibo's technical teams. It significantly improves the performance and stability of training the model for massive small files. The distributed training scenarios with multiple nodes and GPUs can accelerate model training by 18 times.
1. Background
Sina Weibo is the largest social media platform in China. Every day, hundreds of millions of pieces of content are generated and spread on it. The following figure shows the business ecosystem of Weibo. Quality content producers generate and spread premium content. Other users can enjoy this content and follow the microbloggers they like. Thus, interaction is established, and a sound closed-loop ecosystem is formed.
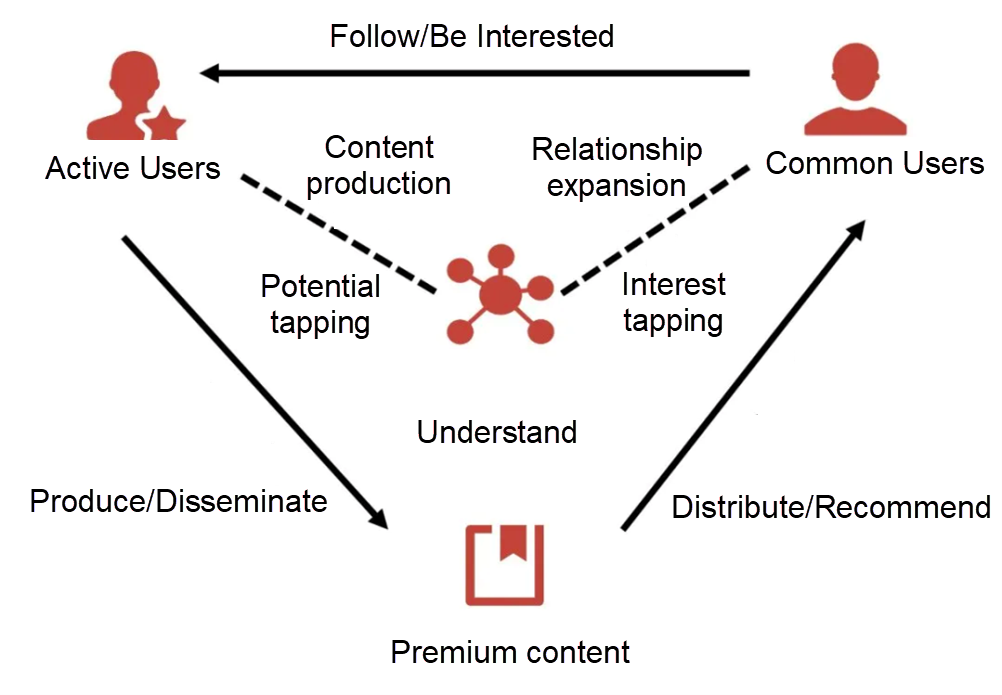
The main function of Weibo's machine learning platform is to make the whole process operate more efficiently and smoothly. With an understanding of the quality content, the platform builds the user profiles and pushes the content that interests users. This allows users to interact with the content producers and encourages producers to produce more (and better) content. As a result, a win-win situation for both information consumers and producers is created. As multimedia content becomes mainstream, deep learning technology becomes more important. From the understanding of multimedia content to the optimization of CTR tasks, the support of deep learning technology is indispensable.
2. Challenges of Training Large-Scale Deep Learning Models
With the widespread use of deep learning in Weibo's business scenarios, its deep learning platform plays a central role. The platform decouples computing resources from storage resources by separating storage and computing. Thus, it provides flexible resource allocation, realizes convenient storage expansion, and reduces storage costs.
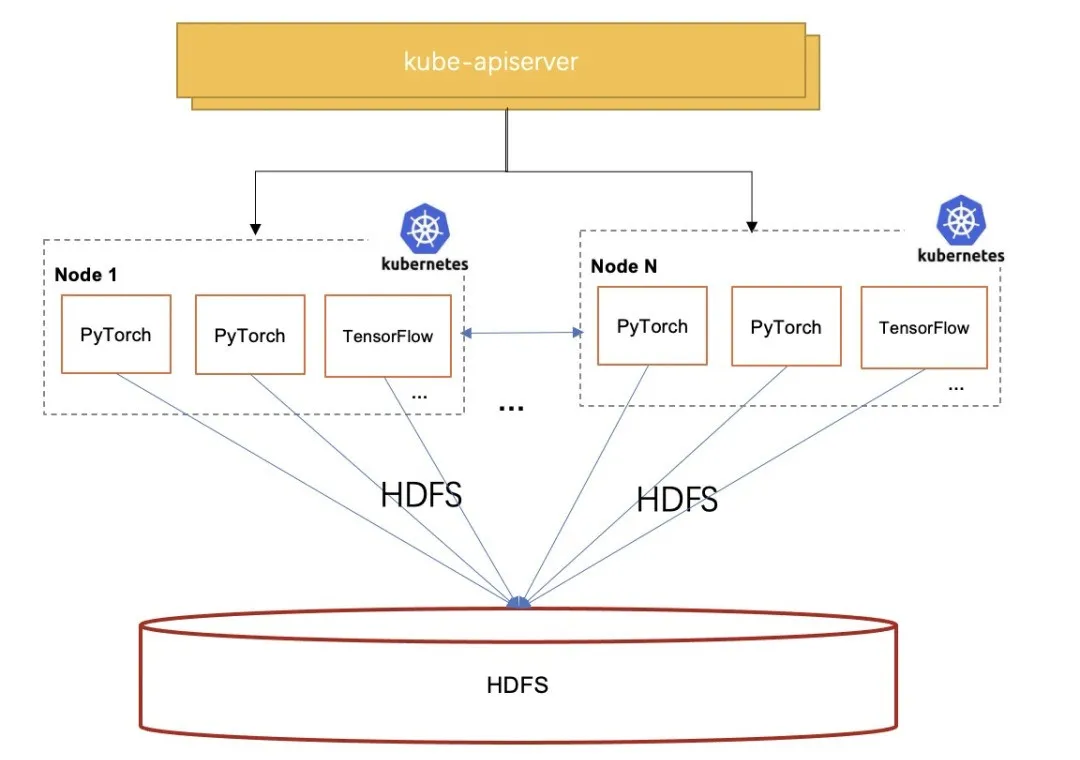
However, this architecture also brings some challenges, among which the most critical ones are data access performance and stability.
-
The separation of computation and storage leads to high latency in data access and slows down training. Deep learning tasks (image or speech models) used by the business team will access massive small files. Tests have shown that the performance of HDFS reading a large number of small files differs from local reading by 10-100 times.
-
Kubernetes scheduler is not aware of data cache, and accessing the same data source after running multiple times is still very slow. Some deep learning tasks access the same data repeatedly at runtime, which includes tasks with the same model but different hyperparameters, tasks with fine-tuning model and the same input, and tasks of AutoML. They generate reusable data cache. However, the native Kubernetes scheduler is not cache-aware. Therefore, the result of application scheduling is not good, the cache cannot be reused, and the performance cannot be improved.
-
Most deep learning frameworks lack support for HDFS interfaces, making the development difficult. Frameworks such as PyTorch and MxNet only support POSIX interfaces, and HDFS interfaces require additional development for adaptation. Therefore, it is necessary to support the POSIX interface in the model development phase and the HDFS interface in the model training phase. As a result, we need to introduce model code to adapt to the complexity of different storage.
-
HDFS becomes a bottleneck for concurrent data access, bringing challenges to stability. Hundreds of GPU machines on Weibo's machine learning platform will access HDFS clusters concurrently during simultaneous training. At the same time, the I/O pressure of deep learning training is relatively high. HDFS service becomes a single point of performance, which poses a huge challenge to the performance and stability of HDFS. Once a task slows down the HDFS system, other training tasks will also be affected. Moreover, once HDFS fails, the entire training cluster will also be affected.
Through the monitoring and analysis of Weibo's machine learning platform, we found that due to the limitation of I/O performance, expensive computing resources such as GPU cannot be fully utilized. In addition, the resource usage of memory and local hard disk in the cluster is very low as most of the space is unused and stable. This happens because most deep learning tasks do not use local disks, and the memory usage is not high. Therefore, we believe that it is a better solution if the memory and disk resources of the cluster can be fully utilized to speed up data access.
3. Fluid + JindoRuntime Provide Efficient Support for Weibo's Machine Learning Platform
We need to achieve better data locality to meet the computational requirements of large-scale deep learning model training. We want to achieve the following goals:
-
Computation can take full advantage of localization to access data, so data does not need to be read repeatedly via the network. This will speed up the training of deep learning model and increase the GPU usage of cluster.
-
The load pressure on HDFS can be reduced. The latency of data access can be reduced, and the availability of HDFS can be improved by reading part of the data locally.
-
The advantages of cache nodes for hot data sets can be maximized. Therefore, they can intelligently schedule tasks to data cache nodes without user perception. Finally, common model training programs can be faster.
-
Data can be read through the POSIX interface. This eliminates the need to use different data access interfaces during the model development and training phases. Consequently, the cost of developing deep learning model programs is reduced.
We are eager to find software with distributed cache acceleration capabilities on Kubernetes to achieve these goals. Fortunately, we found Fluid, a CNCF Sandbox project that met our demands. Therefore, we have designed a new architecture scheme based on Fluid. After verification and comparison, we chose JindoRuntime as the acceleration run time.
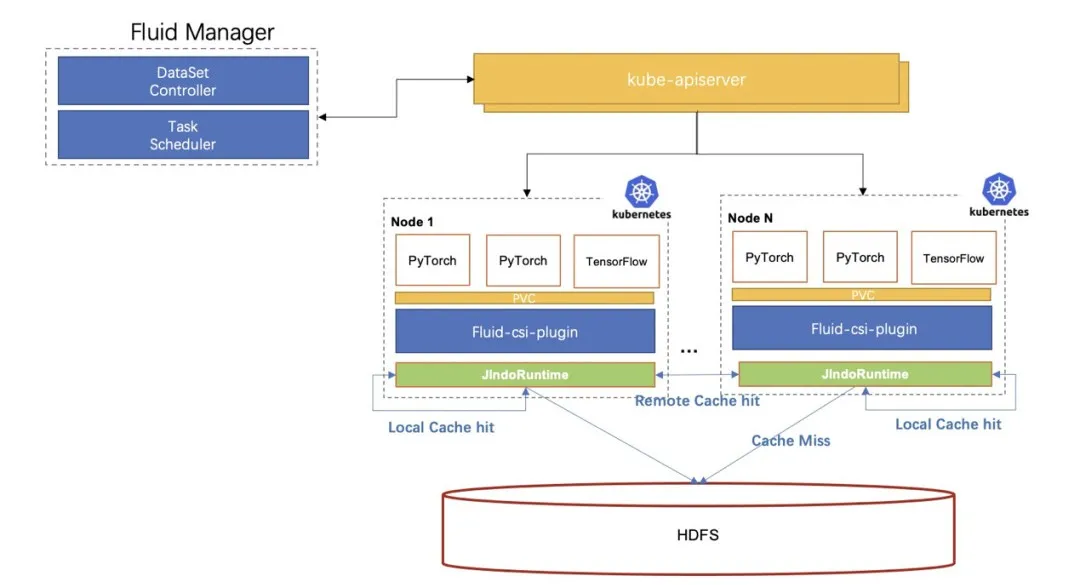
3.1 An Introduction to Architecture Components
3.1.1 Fluid
Fluid [1] is an extensible distributed data orchestration and acceleration system running on Kubernetes. It orchestrates data and schedules the applications that use data. As solves the pain points that the cloud-native orchestration framework faces when running such applications, such as the high latency of data access, the difficulty in the joint analysis of multiple data sources, and the complex process of using data.
3.1.2 JindoRuntime
JindoRuntime [2] is a distributed cache runtime implementation of Fluid based on the JindoFS distributed cache acceleration engine. JindoFS is an engine for optimizing big data storage, which is developed by the Alibaba Cloud EMR Team. It is fully compatible with the Hadoop file system interface and brings clients more flexible and efficient computing and storage solutions. JindoRuntime uses JindoFS's cache mode to access and cache remote files. It supports access and cache acceleration for various storage products such as OSS, HDFS, and AWS S3. The process of using and deploying JindoRuntime on Fluid is simple. It is compatible with the native Kubernetes environment and provides out-of-the-box features. It deeply integrates the features of OSS and optimizes performance with the Native framework. It also supports on-cloud data security features, such as password-free and checksum verification.
3.2 Reasons for Choosing JindoRuntime-Based Fluid
-
Fluid can orchestrate datasets in Kubernetes clusters to achieve the same placement of data and computing. It can also provide interfaces based on Persistent Volume Claim to connect to applications on Kubernetes seamlessly. At the same time, JindoRuntime provides acceleration for accessing and caching data on HDFS. With the POSIX file system interface of FUSE, we can easily work with the massive files on HDFS just like a local disk. Deep learning training tools, such as PyTorch can read the training data using the POSIX file interface.
-
JindoRuntime has made specified optimizations on data organization, management, and access performance of small files for the performance problem of remote data access of large amounts of small files. JindoRuntime can provide efficient access performance for small files, which is much better than accessing HDFS directly.
-
It provides distributed and hierarchical caching of metadata and data and efficient retrieval of small files.
-
It provides a data prefetching mechanism to avoid data access competition caused by pulling data during the training process.
-
It organizes file data with slab allocation and utilizes cache space efficiently.
-
With the data perception and scheduling capability of Fluid, users can place tasks in nodes with cached data without knowing the information of cached nodes. This maximizes the advantages of data access performance.
-
It provides different cache policies and storage methods for small and large files. It has good adaptability to AI training scenarios with small files, and no configuration is required.
3.3 Practices
-
Select Appropriate Cache Nodes: With JindoRuntime, we can enjoy better local data performance. In production, we have found that using all cache nodes for storage does not necessarily bring better performance. The reason is that the disk and network I/O performance of some nodes is not very good. We need to select cache nodes with large-capacity disks and better networks to solve this problem. Fluid supports the schedulability of datasets, namely the schedulability of cache nodes. We schedule cache nodes of datasets by specifying the nodeAffinity of datasets to ensure that cache nodes provide cache services efficiently.
-
Specify the Scheduling Policy for Master Nodes: JindoRuntime consists of three parts: master, worker, and fuse. Master is the head of clusters and is responsible for the management of metadata and cluster cache. Therefore, the master node has strong reliability and a fast speed of failure recovery. During the production, we found that a single master has strong reliability and a fast speed of failure recovery. An important factor that affects the stability of master nodes is the stability of the host. For example, full disks and communication failure of the host will affect the stability of master nodes. Based on this, we use nodeselector for master nodes to select the host with better performance as the master container environment to ensure the stability of the master environment.
-
Prefetch the Data Regularly: An important step before training is to prefetch the metadata and data. Fluid provides metadata and data caching in the form of CRD. Before training, the metadata and data of training files are cached locally, which can accelerate the training substantially. However, the training files stored on HDFS are updated once a day, so the data prefetching process needs to be performed periodically and regularly. Based on the CRD of dataload, we use cronJob to perform periodic scheduling. By doing so, the metadata and data can be prepared before training to ensure efficient training. Of course, JindoRuntime also supports incremental synchronization, so only files that are changed need to be updated each time. This speeds up data prefetching substantially.
3.4 Performance Test Scheme
We have verified the overall effect of the solutions above from different aspects, such as stability and performance. Then, we focus on the performance test scheme. The training models are all video understanding models based on mmaction and adopt the rawframes_train method. It is a test of the training dataset with 4,000,000 pictures. The data is obtained from 400,000 videos extracted from real business scenarios with 10 frames per scenario. Due to the different video definitions, the size of each picture ranges from a few KB to a dozen MB. The total size is about 780 GB, with each cache node providing 300 GB of cache space. In our experience, model convergence is typically achieved around 50 epochs.
When we adjust the data volume of the tested video to 1,000,000, the total data size is 2 TB. Due to the massive data volume and high latency, the HDFS interface mode could not work at all, while Fluid with JindoRuntime could meet the requirements of the business.
Fluid JindoRuntime is used to prefetch data and train models.
3.5 Results of Performance Testing
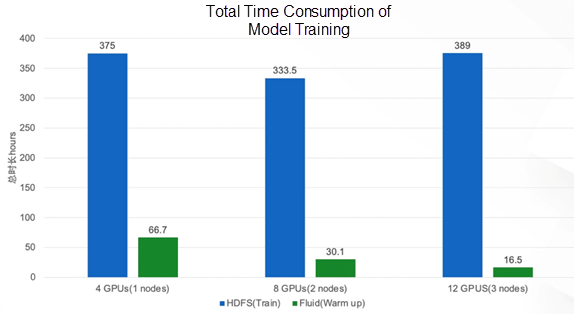
Combined with the solution of Fluid + JindoRuntime, we have achieved an improvement in the training speed after data prefetching. As shown in the figure below, in the scenario of 3 nodes and 12 GPUs, the test of reading data through the HDFS interface is often interrupted due to problems, such as poor network communication. This leads to test failure. After adding exception handling, the waiting time between workers becomes longer. As a result, the increasement of GPUs slows down training rather than speeds up it. The overall training speed is virtually the same in the scenario of 1 node and 8 GPUs as well as 3 nodes and 12 GPUs, and the computing resources are scaled out. Through the new scheme, we found that compared with the HDFS interface, the scenario of 1 node and 4 GPUs can be accelerated by 5 times, 2 nodes and 8 GPUs by 9 times, and 3 nodes and 12 GPUs by 18 times.
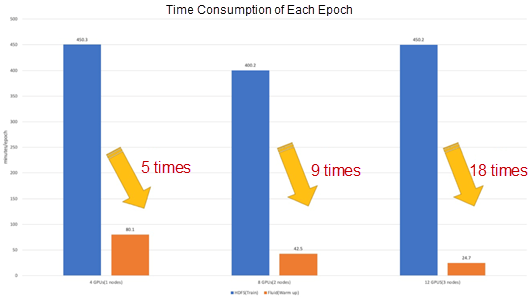
Since speed and stability of training are guaranteed, the model’s end-to-end training time has also been reduced from 389 hours (16 days) to 16 hours.
4. Summary
After the integration of Fluid and JindoRuntime, the performance and stability of model training in small file scenarios are improved significantly. In the distributed training of multiple nodes and multiple GPUs, the model training speed can be increased by 18 times. Training that used to take two weeks and now only takes 16 hours. Shorter time for training and less pressure on HDFS also improve the stability of training tasks, with the success rate increasing from 37.1% to 98.3%. The amount of data in our production environment is currently 4 TB and will continue to grow with continuous iteration.
Weibo AI training scenarios have high requirements on data reading performance, and a large number of small files are also very sensitive to access latency. The caching capability of JindoRuntime can accelerate the caching of data in big data storage systems effectively. It provides stable and reliable data access performance with high throughput and low latency. At the same time, it can relieve the pressure on the backend storage system and ensure the stability of the backend storage. Optimization of small file reading and caching for specific scenarios can relieve the I/O pressure on HDFS clusters and improve training efficiency.
5. Outlook
Currently, Fluid + JindoRuntime is more of a trump card that accelerates small filescenarios, rather than a conventional weapon that accelerates and optimizes all data sets. We hope that flexible data acceleration can be used as the differentiation capability of the Weibo deep learning platform to improve the overall training task speed and the utilization of computing resources. We also hope to help the community continue to evolve and help more developers. Specifically:
- Support scheduled tasks and dynamic scale-in and scale-out
- Improve performance of data prefetching, provide metadata backup mechanism, and realize the rebuilding of data sets
- Provide a performance monitoring console
- Support high availability for Runtime metadata and image upgrades
- Support full lifecycle management of multiple datasets in a scale Kubernetes cluster
Acknowledgement
Thanks to Chenshan and Yangli of the Alibaba Cloud JindoFS Team and Cheyang of the Container Team for all their help during the designing and optimization process. They have endowed existing applications with data acceleration capabilities without any application transformation. They have also provided timely and professional support for requirements and problems in the testing and production environments.
References
For more information about Fluid and JindoFS, please refer to the links below:
Click the following link for our project on GitHub!